1. 개념 설명
(1) 해시 테이블은 키(key)를 값(value)에 매핑할 수 있는 구조인, 연관 배열 추가에 사용되는 자료 구조이다.
2. 과정
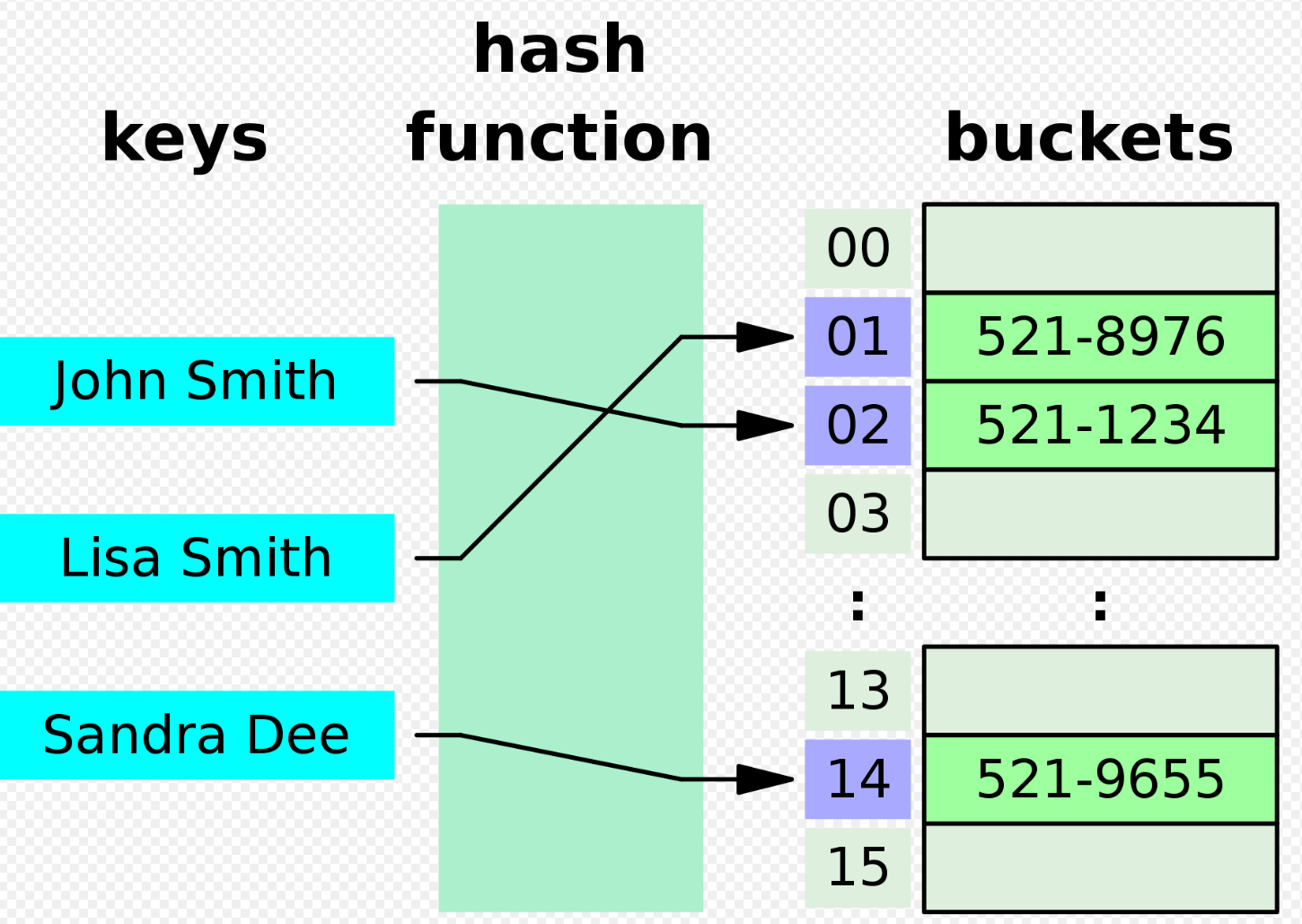
- 실제로 수행되는 과정이며, key값을 가지고 해당하는 index위치에 가서 buckets에 있는 value에 매핑하고 있다.
- 아래는 실제 3. 코드에서 진행되는 과정 중 하나이며, 이것을 이해하면 코드를 쉽게 이해할 수 있을 것이다.
|
1. apple이 들어옴.
getHashkey(apple)의 결과 2가 나옴.
length[2]는 0이므로 처음 들어온 값임.
s_data[2][0]에 apple을 저장함. length[2]를 ++함.
2. abc가 들어옴.
getHashKey(abc)의 결과 2가 나옴.
length[2]는 1이므로 이미 들어온 값임.
length[2]만큼 반복하면서 s_data에 abc라는 데이터가 있는지 확인함.
s_data[2][0]은 apple이므로 일치하는 값이 없음.
s_data[2][1]에 apple을 저장함. length[2]를 ++함.
3. abc가 들어옴.
getHashKey(abc)의 결과 2가 나옴.
length[2]는 2이므로 이미 들어온 값임.
length[2]만큼 반복하면서 s_data에 abc라는 데이터가 있는지 확인함.
s_data[2][1]은 abc이므로 일치함.
data[2][1] 값을 1 증가 후. 1을 리턴함.
[출력값]
OK
OK
abc1
|
cs |
3. 코드
: 이 코드는 아래 링크에 있는 해시 테이블의 문제이다.
조건은 아래와 같다.
|
1. 처음 생성되는 문자열 key 값에는 "OK", 이미 존재하는 문자열 key 값에는 "문자열+index"로 출력한다.
2. Input과 Output의 예시는 아래와 같다.
[Input]
5
abcd
abc
abcd
abcd
ab
[Output]
OK
OK
abcd1
abcd2
oK |
cs |
|
public class HashTable {
static final int HASH_SIZE = 1000;
static final int HASH_LEN = 500;
static final int HASH_VAL = 19;
//최대한 해시 충돌 방지를 위해 소수(ex) 17, 19 등)으로 잡는다. static int[][] data = new int[HASH_SIZE][HASH_LEN];
//입력값을 저장하는 변수 static int[] length = new int[HASH_SIZE];
// 현재 key에 담긴 수를 저장하는 변수 static String[][] s_data = new String[HASH_SIZE][HASH_LEN];
//입력 값으로 받은 문자열을 저장하는 변수 static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static StringBuilder sb = new StringBuilder();
static int N; // 총 입력받는 개수
static String str; // 라인 입력받는 변수
public static void main(String[] args) throws Exception {
N = Integer.parseInt(br.readLine()); // 입력 수 (1~100000)
for (int i = 0; i < N; i++) {
str = br.readLine();
int key = getHashKey(str);
int cnt = checking(key);
if(cnt != -1) { // 이미 들어왔던 문자열
sb.append(str).append(cnt).append("\n");
}else {
sb.append("OK").append("\n");
}
}
System.out.println(sb.toString());
}
static int getHashKey(String str) {
int key=0;
for(int i=0; i<str.length(); i++) {
key = (key*HASH_VAL) + str.charAt(i);
}
// key값은 배열 인덱스를 활용하기 때문에
// 만약 음수라면 -> 양수로 바꿔준다.
if(key<0) key = -key;
return key%HASH_SIZE;
}
static int checking(int key) {
int len = length[key];
if(len != 0) { // 이미 들어온 적 있음
for (int i = 0; i < len; i++) { // 이미 들어온 문자열이 해당 key 배열에 있는지 확인
if(str.equals(s_data[key][i])) {
data[key][i]++;
return data[key][i];
}
}
}
// 들어온 적이 없었으면 해당 key배열에서 문자열을 저장하고 길이 1 늘리기
s_data[key][length[key]++] = str;
return -1;
}
}
|
cs |
4. 시간 복잡도
(1) 최선과 평균의 시간복잡도는 O(1)이며, 최악은 O(N)이다.
5. 장점
(1) 완전탐색(Brute Force)에 빠지는 알고리즘 문제들을 해시로 적용하여 최대한 모든 데이터를 탐색할
필요없이 값(value)를 구할 수 있다.
(2) 해시 충돌이 없는 상태에서의 배열 또는 리스트, 트리와 같은 선형적인 구조보다 더 빠른 탐색이 가능하다.
6. 단점
(1) 아무리 많은 키(key)값을 만들더라도 같은 키 값을 가지는 서로 다른 값(value)이 존재할 수 있다.
( 이것을 우리는 해시 충돌이라고 부른다. )
(2) 만약 해시 충돌이 발생한다면, 시간 복잡도는 O(N)에 점점 수렴하게 된다.
(3) 정렬이나 순차적인 메모리 저장이 필요한 경우 적합하지 않다.
7. 해시 출동을 해결하는 기법 2가지
(1) 분리 연결법 (Separate Chaining)
: 동일한 버킷의 데이터에 대해 자료구조를 활용해 추가 메모리를 사용하여 다음 데이터의 주소를 저장하는 방법이다.
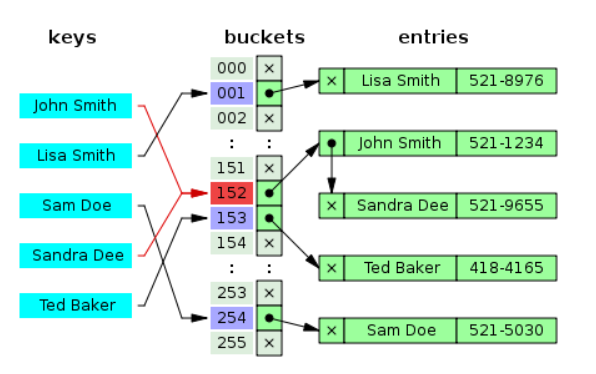
(2) 개방 주소법 (Open Addressing)
: 추가적인 메모리를 사용하는 분리 연결법 방식과 다르게 비어있는 해시 테이블의 공간을 활용하는 방법이다.
( 아래와 같이 세 가지 방법이 존재한다. 여기서는 자세하게 다루지 않으므로, 한번 인터넷에 찾아보면 좋을 것 같다. )
1. Linear Probing
2. Quadratic Probing
3. Double Hasing Probing

8. 참고한 사이트
'알고리즘 (with JAVA) > 기본 알고리즘' 카테고리의 다른 글
| BFS (Breadth First Search) (0) | 2023.05.05 |
|---|---|
| DFS (Depth First Search) (0) | 2023.05.05 |
| 이진 탐색 (Binary Search) (0) | 2023.04.29 |
| 계수 정렬 (Counting Sort) (0) | 2023.04.29 |
| 기수 정렬 (Radix Sort) (0) | 2023.04.29 |